Generative Pre-Trained Transformer (GPT)
Introduction
I have already provided an overview of Large Language Models (LLMs) here. Now, I would like to focus on Generative Pre-trained Transformers (GPT), which have recently gained significant attention.
GPT are a type of language model that combines generative capabilities, pre-training on large text, and the Transformer architecture. GPT models generate coherent and contextually relevant text based on an input prompt, making them useful in tasks like text completion, summarization, and dialogue systems.
The “pre-training” refers to the model’s initial phase of being trained on vast amounts of text, which allows it to learn language patterns, grammar, and context before being fine-tuned on specific tasks.
The Transformer component, specifically the decoder-only architecture, enables efficient text generation by attending to all positions in the input sequence simultaneously. This eliminates the limitations of recurrent networks and allows GPT to handle long-range dependencies effectively.
Generation mechanism
A trained language model generates text by leveraging patterns it has learned during training. Optionally, input text can be provided, which influences the model’s generated output. During training, the model is exposed to vast amounts of text, from which it learns to predict the next word in a sequence. Each prediction starts off inaccurate, and the error is calculated to update the model for improved accuracy in future predictions.
This process is repeated many times, allowing the model to encode its learned knowledge into several billion parameters. These parameters are then used to determine which token to generate with each run. Initially, the model begins with random parameters, but through training, it converges to values that result in better text generation.
The model operates within a context window, which is a fixed-size portion of the input text that the model can attend to when generating new tokens. The size of this context window limits how much prior text the model can consider when making predictions. If the input exceeds this window, earlier tokens are ignored. Larger context windows allow the model to handle longer sequences, providing more context for generating relevant and coherent outputs.
The user can optionally provide a prompt (a set of instructions or initial text), which comes into play at the start of the text generation process. This prompt sets the initial context within the model’s fixed-size context window, guiding the model’s predictions. The prompt helps frame the generated output, ensuring that the text continues coherently and is relevant to the instructions or context provided. As the model generates new tokens based on the prompt, if the combined input and generated text exceed the context window, the earliest tokens are dropped, and the model focuses on the most recent tokens.
When generating text, the process begins by converting each input word into a vector—a list of numbers that numerically represents the word. These vectors are then processed through a stack of transformer decoder layers, each layer containing billions of parameters that perform intricate calculations to predict the next word in the sequence.
After processing, the resulting vector is converted back into a word, completing the generation cycle. This sequence of converting words to vectors, processing them through the transformer layers, and converting the output vectors back to words enables the model to generate coherent and contextually appropriate text based on the input it receives.
As I also explained in my previous post, a model can be fine-tuned by updating its weights to improve performance on specific tasks. Fine-tuning adjusts the pre-trained model’s parameters to better align with the requirements of a particular dataset or application, allowing the model to generate more accurate and task-specific outputs.
Basic model implementation
I will now implement a sample GPT which is trained on Dante Alighieri Divina Commedia text.
Tokenizer
A tokenizer is a fundamental tool in natural language processing (NLP) that transforms raw text into a sequence of tokens. Tokens are the basic units of meaning—such as words, subwords, or characters—that algorithms and models use to process and understand text data. Tokenization serves several critical purposes:
-
Normalization: It helps standardize text by converting it into a consistent format, such as lowercasing all words or removing punctuation.
-
Segmentation: It breaks down complex text into manageable pieces, making it easier for models to analyze patterns and relationships.
-
Numerical Mapping: It converts tokens into numerical representations (usually integers), enabling their use as inputs in machine learning models.
Without tokenization, models would struggle to interpret the raw text, as they require numerical inputs to perform computations.
Now, we will build a tokenizer using PyTorch. The tokenizer will read text from a file, split it into tokens, map each token to a unique integer, convert the sequence of tokens into a PyTorch tensor, and save it.
Below is the Python code that accomplishes this:
import torch
# Set a fixed random seed for reproducibility
torch.manual_seed(42)
# Read the input file
with open('./build/input.txt', 'r', encoding='utf-8') as f:
text = f.read()
# Tokenize the text by splitting on whitespace
tokens = text.split()
# Create a vocabulary mapping each unique token to a unique integer
vocab = {token: idx for idx, token in enumerate(sorted(set(tokens)))}
# Convert the list of tokens into a list of token IDs
token_ids = [vocab[token] for token in tokens]
# Convert the list of token IDs into a PyTorch tensor
token_tensor = torch.tensor(token_ids, dtype=torch.long)
# Output some information about the tokenization
print("Vocabulary Size:", len(vocab))
print("First 10 Tokens:", tokens[:10])
print("First 10 Token IDs:", token_ids[:10])
print("Token Tensor Shape:", token_tensor.shape)
The output will would be similar to:
Vocabulary Size: 20978
First 10 Tokens: ['LA', 'DIVINA', 'COMMEDIA', 'di', 'Dante', 'Alighieri', 'INFERNO', 'Inferno:', 'Canto', 'I']
First 10 Token IDs: [1643, 1143, 927, 6677, 1154, 720, 1534, 1574, 961, 1530]
Token Tensor Shape: torch.Size([96770])
Data loader
A data loader in PyTorch is an abstraction that provides an efficient way to iterate through large datasets. It allows batching, shuffling, and parallel loading of data, which is especially useful during the training of models. The data loader wraps a dataset and returns an iterator over the data, enabling easy access to mini-batches during training and evaluation.
For effective training, datasets are typically split into two (or more) subsets:
- Training set: This portion of the data is used to train the model.
- Evaluation (or validation) set: This part is reserved to evaluate how well the model generalizes to unseen data, helping prevent overfitting.
We will now build a basic data loader that splits the tokenized dataset into training and evaluation sets.
Below is the Python code for this section:
import torch
from torch.utils.data import Dataset, DataLoader
# Parameters
# Define data loaders for training and evaluation
batch_size = 32
# Define the split ratio between training and evaluation
split_ratio = 0.8
# Load the tokenized data
data = torch.load('./build/tokenized_data.pkl', weights_only=False)
# Extract the token tensor
token_tensor = data['token_tensor']
# Set a fixed random seed for reproducibility
torch.manual_seed(4852)
num_train = int(len(token_tensor) * split_ratio)
# Split the dataset into training and evaluation sets
train_tensor = token_tensor[:num_train]
eval_tensor = token_tensor[num_train:]
# Define a simple dataset wrapper
class TokenDataset(Dataset):
def __init__(self, data_tensor):
self.data_tensor = data_tensor
def __len__(self):
return len(self.data_tensor)
def __getitem__(self, index):
return self.data_tensor[index]
# Create training and evaluation datasets
train_dataset = TokenDataset(train_tensor)
eval_dataset = TokenDataset(eval_tensor)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
eval_loader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=False)
# Example: Iterate over one batch in the training set
for batch in train_loader:
print("Training batch shape:", batch.shape)
break
# Example: Iterate over one batch in the evaluation set
for batch in eval_loader:
print("Evaluation batch shape:", batch.shape)
break
The output will would be similar to:
Training batch shape: torch.Size([32])
Evaluation batch shape: torch.Size([32])
This data loader provides an efficient way to access the tokenized data in batches, ready to be fed into the GPT model for training and evaluation.
Training a basic model
Now that we have created a dataloader, we can start training the model.
Parameters
The parameters used are as follows:
train_batch_size = 16
eval_batch_size = 8
# Number of tokens processed in a single sequence
context_length = 512
train_split = 0.7 # Percentage of data to use for training
Train_dataset = TokenDataset(train_tensor, context_length)
eval_dataset = TokenDataset(eval_tensor, context_length)
train_loader = DataLoader(train_dataset, batch_size=train_batch_size,
shuffle=True)
eval_loader = DataLoader(eval_dataset, batch_size=eval_batch_size,
shuffle=False)
The context length refers to the maximum number of tokens that the model processes in one input sequence. In this case, the context length is set to 512, meaning that each training example will consist of up to 512 tokens. The model will learn to predict the next token based on these 512 tokens, helping it capture dependencies between words over a limited window.
In PyTorch, the context_length is passed to the dataset class, which prepares sequences of that length from the tokenized data. This ensures that when the dataloader retrieves batches, each sequence has the correct number of tokens, providing a fixed-length input for the model. Keeping the context length manageable is important because increasing it significantly increases memory usage and computation time.
This approach is widely used in transformer-based models like GPT because it allows the model to capture both short- and long-range dependencies within the token sequence, up to the limit of the context length.
Initialization
Then we can initialize the model:
# used to define size of embeddings
d_model = 1024
# Initialize model
model = GPT(vocab_size=vocab_size, d_model=d_model).to(device)
The variable d_model defines the size of the embeddings, which will represent each token in the sequence. The GPT model is initialized with the vocab_size (number of tokens in the vocabulary) and d_model (the dimensionality of the token embeddings). The model is moved to the specified device.
class MyGPT(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
# Word token embeddings
self.wte = nn.Embedding(vocab_size, d_model)
# Final layer norm
self.ln_f = nn.LayerNorm(d_model)
# Output layer
self.fc_out = nn.Linear(d_model, vocab_size)
In the MyGPT class, the constructor defines the layers. self.wte creates an embedding layer where each token from the vocabulary is mapped to a dense vector of size d_model. self.ln_f normalizes these embeddings to stabilize training, and self.fc_out is the final linear layer that maps the processed embeddings back to the size of the vocabulary to predict the next token.
def forward(self, inputs, targets=None):
# (batch_size, sequence_length, d_model)
embeddings = self.wte(inputs)
# (batch_size, sequence_length, vocab_size)
logits = self.fc_out(self.ln_f(embeddings))
The forward method performs the forward pass of the model. First, the input tokens are converted into embeddings using the wte layer. These embeddings are passed through the layer normalization (ln_f) and then fed to the output layer (fc_out) to produce logits. The shape of logits will be (batch_size, sequence_length, vocab_size).
loss = None
if targets is not None:
batch_size, sequence_length, vocab_size_out = logits.shape
logits = logits.reshape(batch_size * sequence_length, vocab_size_out)
targets = targets.reshape(batch_size * sequence_length)
loss = F.cross_entropy(logits, targets)
If target labels are provided (i.e., during training), the model calculates the cross-entropy loss. Both logits and targets are reshaped to match the expected shape for the loss computation. The loss is computed using F.cross_entropy.
return logits, loss
The method returns the predicted logits and the loss (if targets are provided). If no targets are given, only the logits are returned for inference.
Training routine
# Initialize optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
The optimizer is initialized using Adam, a commonly used variant of gradient descent. The model.parameters() function provides all the parameters of the model that need to be updated, and lr is the learning rate that controls the step size during optimization.
for epoch in range(num_epochs):
model.train()
total_loss = 0
The training loop runs for a fixed number of epochs (num_epochs). At the start of each epoch, the model is set to training mode with model.train(), and total_loss is initialized to zero to accumulate the loss over the entire epoch.
for batch in train_loader:
# Take all tokens except the last one as inputs
inputs = batch[:, :-1].to(device)
# Shift inputs by one token for targets
targets = batch[:, 1:].to(device)
In each batch of the training loop, the input tokens (inputs) are selected from the sequence by excluding the last token. The targets are the shifted sequence, starting from the second token onward. This prepares the model to predict the next token in the sequence.
optimizer.zero_grad()
logits, loss = model(inputs, targets)
loss.backward()
optimizer.step()
Before each update, optimizer.zero_grad() clears the previously accumulated gradients. Then, the model computes the logits and the loss using the forward pass. The loss.backward() function computes the gradients with respect to the model parameters, and optimizer.step() updates the parameters using those gradients.
total_loss += loss.item()
The loss for the current batch is added to total_loss, which keeps track of the cumulative loss for the entire epoch.
avg_tl = total_loss / len(train_loader)
t1 = print_time(t1, f"Epoch [{epoch}/{num_epochs}], Loss: {avg_tl:.4f}")
At the end of the epoch, the average training loss (avg_tl) is calculated by dividing the total_loss by the number of batches in the training data. The function print_time outputs the epoch number and the average training loss.
model.eval()
eval_loss = 0
with torch.no_grad():
for batch in eval_loader:
inputs = batch[:, :-1].to(device)
targets = batch[:, 1:].to(device)
logits, loss = model(inputs, targets)
eval_loss += loss.item()
After training, the model switches to evaluation mode with model.eval(), which disables certain layers like dropout. The torch.no_grad() context is used to disable gradient calculation, improving memory usage and speed. Similar to training, the model is evaluated on the validation data, with inputs and targets prepared in the same way.
avg_evl = eval_loss / len(eval_loader)
t1 = print_time(t1, f"Epoch [{epoch}/{num_epochs}], Eval Loss: {avg_evl:.4f}")
At the end of validation, the average evaluation loss (avg_evl) is calculated. The function print_time outputs the epoch number and the average evaluation loss for monitoring the model’s performance.
# Save model configuration and state_dict together
torch.save({
'vocab_size': vocab_size,
'd_model': d_model,
'state_dict': model.state_dict()
}, './build/gpt_model.pth')
At the end of training, the model’s configuration and weights are saved using torch.save(). The dictionary being saved contains the vocab_size, d_model, and the state_dict() of the model, which holds all the trained parameters (weights and biases). This allows for the model to be easily reloaded later for inference or further training.
In conclusion, saving the model’s state (specifically the weights) ensures that it can be reused later without the need for retraining. While the training process can be very time-consuming, especially for large transformer models, decoding (or inference) is much faster, as it only involves passing the input through the model using the precomputed weights. This is a typical approach in transformer-based architectures like GPT. The model can be deployed and used for generating sequences quickly, making it highly efficient for real-time applications.
Running the model
The model was trained for 150 epochs. Below is a snippet of the training progress:
Epoch [62/150], Loss: 3.2082, Eval Loss: 10.2417
Epoch [63/150], Loss: 3.1745, Eval Loss: 10.2798
Epoch [64/150], Loss: 3.2108, Eval Loss: 10.3174
...
Epoch [147/150], Loss: 3.1096, Eval Loss: 10.7648
Epoch [148/150], Loss: 3.1270, Eval Loss: 10.7553
Epoch [149/150], Loss: 3.1151, Eval Loss: 10.7537
Epoch [150/150], Loss: 3.1191, Eval Loss: 10.7783
As observed, the training loss barely changed between epochs 60 and 150, indicating that the model’s improvement plateaued. Given the simplicity of the model, this result is expected. The next step is to use this trained model for text prediction.
In this logic the text is generated based on an initial input sequence. We begin by loading the trained GPT model, the tokenized vocabulary, and other parameters required for text generation:
tokenizer_data = torch.load('./build/tokenized_data.pkl', weights_only=False)
vocab = tokenizer_data['vocab']
id_to_token = {idx: token for token, idx in vocab.items()}
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
checkpoint = torch.load('./build/gpt_model.pth', weights_only=False)
vocab_size = checkpoint['vocab_size']
d_model = checkpoint['d_model']
model = GPT(vocab_size=vocab_size, d_model=d_model).to(device)
model.load_state_dict(checkpoint['state_dict'])
model.eval()
The tokenizer converts text into token IDs, and a reverse mapping (id_to_token) is created to map token IDs back to human-readable text. The trained model is then loaded, and it is placed into evaluation mode.
The generate_text function accepts a starting sequence of text and a maximum number of new tokens to generate. First, the input text is encoded by converting the words into corresponding token IDs using the vocabulary dictionary:
input_ids = [vocab[token] for token in start_sequence.split()]
input_ids = torch.tensor(input_ids, dtype=torch.long).unsqueeze(0).to(device)
The tokenized input is then fed into the model to predict the next tokens. The model generates text iteratively, adding one token at a time to the existing sequence. The generate method handles this process:
def generate(self, input_ids, max_new_tokens, temperature=1.0, top_k=10):
generated_ids = input_ids.squeeze(0).tolist()
context_length = input_ids.size(1)
The generation loop runs for max_new_tokens iterations. During each iteration, the model is provided with the current token sequence. The logits (the raw output scores from the model) are calculated for the next possible tokens:
input_tensor = torch.tensor(generated_ids[-context_length:], dtype=torch.long).unsqueeze(0).to(input_ids.device)
logits, _ = self.forward(input_tensor)
next_token_logits = logits[:, -1, :]
Temperature scaling is applied to adjust the randomness of the output. A higher temperature makes the model more exploratory, while a lower temperature favors more likely tokens:
next_token_logits = next_token_logits / temperature
Top-k sampling is then applied, which limits the possible next tokens to the most likely k candidates. This prevents the model from choosing highly unlikely tokens:
next_token_logits = top_k_logits(next_token_logits, top_k)
The logits are transformed into a probability distribution using the softmax function, and a token is sampled from this distribution:
probs = F.softmax(next_token_logits, dim=-1)
next_token_id = torch.multinomial(probs, num_samples=1).item()
Each newly generated token is appended to the existing sequence of tokens, and the process repeats for the desired number of tokens:
generated_ids.append(next_token_id)
The output is a sequence of token IDs, which is then transformed into words using the id_to_token dictionary:
return torch.tensor(generated_ids, dtype=torch.long).unsqueeze(0).to(input_ids.device)
Finally, the generate_text function is used to invoke the generation, and the text is printed out:
start_sequence = "Nel mezzo del cammin di nostra vita"
generated_sequence = generate_text(model, start_sequence, max_new_tokens=50)
generated_only = generated_sequence[len(start_sequence.split()):]
print("Start sequence:", start_sequence)
print("Generated sequence:", " ".join(generated_only))
The final output is a concatenation of the original input sequence and the newly generated text. The generated text can vary significantly depending on the parameters such as temperature and top-k value, providing either creative or more deterministic results.
Output example
For demonstration purposes, the simple GPT model was used to generate text based on an initial prompt. The model was trained for 150 epochs, but as it is quite basic, the quality of the output is expected to be limited.
We start with a well-known line from Dante’s Divine Comedy:
Nel mezzo del cammin di nostra vita
The model then generates a continuation based on this input. Below is the generated output:
e con le sue picciole onde piegava l'erba e con la sua mi 'ntrassi;
ed è quel ch'elli avea membro e 'l ciel per non ti sia da la mente
a la terra per che tu chi vide mei ciò sia, parole tue fami".
Virgilio li occhi dolenti ne li
As we can observe, the generated text lacks coherence and fails to maintain a meaningful flow, which is expected given the simplicity of the model. Despite the initial structure resembling natural language, the generated continuation quickly becomes disjointed and nonsensical.
This result provides a baseline to which we can compare the improved model once the attention mechanism is added, allowing the model to better capture relationships between tokens in the input sequence.
Advanced Model Implementation
While the basic model produces results, they are not yet impressive. However, several enhancements can significantly elevate the model’s quality. Even a homegrown GPT can achieve decent performance with the right adjustments.
Tokenizer
The quality of the model output depends heavily on the input tokenization process. For this reason, I opted to rely on external libraries that are specifically designed for natural language processing. One such library is tiktoken, which is tailored for tokenizing text in models like GPT-3.
import tiktoken
import re
def simple_tokenizer(text):
# Basic tokenization logic
...
return tokens, vocab
def advanced_tokenizer(text):
# Replace all numbers with a <NUM> token for better generalization
text = re.sub(r'\d+', '<NUM>', text)
# Initialize tiktoken's GPT-3 tokenizer
enc = tiktoken.get_encoding("gpt2")
# Add special tokens
special_tokens = ["<PAD>", "<BOS>", "<EOS>", "<UNK>"]
# Tokenize the text and obtain token IDs
token_ids = enc.encode(text)
# Decode back to tokens for readability
tokens = enc.decode(token_ids).split()
# Prepend special tokens
tokens = special_tokens + tokens
# Create a vocabulary mapping tokens to unique integer indices
vocab = {token: idx for idx, token in enumerate(sorted(set(tokens)))}
return tokens, vocab
For the tokenizer, using a well-established external library is essential to ensure that the input is efficiently processed. In my case, I chose tiktoken as it is designed for natural language modeling and aligns well with the requirements of GPT models.
Data loader
No changes were made to the data loader, as PyTorch already provides efficient and reliable data handling mechanisms. Its built-in utilities guarantee proper preprocessing, batching, and shuffling of data, which are essential for model training.
Positional encoding (PE)
Adding positional encoding (PE) is necessary in transformer architectures, including GPT models, because the attention mechanism itself is “permutation invariant” — meaning it doesn’t inherently know the position of tokens in a sequence. The PE provides a way to inject position information into the model so that it can understand the order of tokens in the input.
The neural network layer, usually a feedforward network applied after the attention mechanism, helps process the information further and improves the model’s ability to capture complex relationships. It’s part of the standard transformer block and helps refine the representations learned by the attention layer.
We will add a sinusoidal positional encoding, commonly used in transformer models.
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # shape: (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x is expected to be of shape (batch_size, seq_len, d_model)
seq_len = x.size(1)
x = x + self.pe[:, :seq_len]
return x
A neural network will act as the post-attention transformation, but for now, we’ll include it before attention. It’s a simple two-layer feedforward network with activation.
class FeedForwardNN(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.fc1 = nn.Linear(d_model, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, d_model)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
These two layers were integrated into the model, and a few runs were made to ensure that the overall model is still properly working before adding the attention mechanism.
Single-head attention
We can now add a single-head attention layer. First the attention layer is created:
class SingleHeadAttention(nn.Module):
def __init__(self, d_model):
super().__init__()
# Linear layers to project inputs into query, key, and value vectors
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
# Scaling factor for stability when computing attention scores
self.scale = 1.0 / math.sqrt(d_model)
This is the SingleHeadAttention class, which implements a single-headed self-attention mechanism. In this setup, three linear layers are used to project the input into query, key, and value vectors. These vectors are crucial for computing the attention scores. The scaling factor is added to the dot-product of the query and key to stabilize the gradients, especially for large values of d_model.
def forward(self, x):
seq_length = x.size(1)
# Project input embeddings into Q, K, and V
# Shape: (batch_size, seq_length, d_model)
Q = self.query(x)
K = self.key(x)
V = self.value(x)
In the forward pass, the input embeddings x are passed through the query, key, and value linear layers to generate the Q, K, and V matrices. These projections are used to compute attention scores and derive the final attention output.
# Compute attention scores
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) * self.scale
# Apply causal mask to prevent attention to future tokens
mask = torch.triu(torch.ones(seq_length, seq_length),
diagonal=1).bool().to(x.device)
attention_scores = attention_scores.masked_fill(mask, float('-inf'))
The attention scores are calculated as the dot product between the query and the transposed key vectors, scaled by the scale factor. This operation computes the similarity between each token in the sequence.
Next, a causal mask is applied. This mask prevents the model from attending to future tokens (i.e., tokens to the right of the current one in the sequence). It is critical for autoregressive models like GPT. The mask is applied by setting the attention scores of future tokens to -inf, effectively blocking them from consideration in the attention mechanism.
# Softmax normalization for attention weights
attention_weights = torch.softmax(attention_scores, dim=-1)
# Compute the weighted sum of the values
attention_output = torch.matmul(attention_weights, V)
return attention_output
The attention scores are converted into probabilities using the softmax function, which normalizes the scores along the sequence length dimension. These normalized weights indicate how much attention each token should pay to other tokens in the sequence.
Finally, the attention weights are used to compute the weighted sum of the values (V), which produces the final attention output. This output is the result of the model attending to relevant parts of the input sequence.
This layer is then added to the model:
class MyGPT(nn.Module):
def __init__(self, vocab_size, d_model, max_len=5000, hidden_dim=2048):
super().__init__()
...
# Attention layer
self.attention = SingleHeadAttention(d_model)
# Feedforward neural network
self.ffn = FeedForwardNN(d_model, hidden_dim)
# Final layer norm
self.ln_f = nn.LayerNorm(d_model)
# Output layer
self.fc_out = nn.Linear(d_model, vocab_size)
In the MyGPT class, we instantiate the SingleHeadAttention layer, along with a feedforward neural network (FFN), layer normalization, and the final output layer. The FFN helps the model capture complex patterns by transforming the attention output before generating the final token predictions.
def forward(self, inputs, targets=None):
...
# Apply attention
attn_output = self.attention(embeddings)
# Pass through feedforward NN
ffn_output = self.ffn(attn_output)
...
return logits, loss
In the forward method, we first pass the input embeddings through the attention layer to compute the attention output. This output is then processed through the feedforward neural network (FFN), which transforms the representation before passing it to the next layers in the model.
Finally, the output logits are computed, and the loss is optionally calculated if target labels are provided during training.
This complete attention implementation allows the GPT model to attend to relevant parts of the input sequence when making predictions, making the model more powerful and capable of generating coherent text.
Multiple-head attention
The final step is to add multiple layers of attention:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, \
"d_model must be divisible by num_heads"
self.num_heads = num_heads
# Dimensionality of each attention head
self.head_dim = d_model // num_heads
# Linear layers to project input into query, key, and value vectors
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
# Final linear layer to project concatenated heads back to d_model
self.fc_out = nn.Linear(d_model, d_model)
self.scale = 1.0 / math.sqrt(self.head_dim)
def forward(self, x):
B, seq_length, d_model = x.shape
# Project input into query, key, and value vectors
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# Split Q, K, V into multiple heads
# Shape: (B, num_heads, seq_length, head_dim)
Q = Q.view(B, seq_length, self.num_heads,
self.head_dim).transpose(1, 2)
K = K.view(B, seq_length, self.num_heads,
self.head_dim).transpose(1, 2)
V = V.view(B, seq_length, self.num_heads,
self.head_dim).transpose(1, 2)
# Compute attention scores
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) * self.scale
# Apply causal mask to prevent attention to future tokens
mask = torch.triu(torch.ones(seq_length, seq_length),
diagonal=1).bool().to(x.device)
attention_scores = attention_scores.masked_fill(mask, float('-inf'))
# Softmax normalization for attention weights
attention_weights = torch.softmax(attention_scores, dim=-1)
# Compute the weighted sum of the values
attention_output = torch.matmul(attention_weights, V)
# Concatenate the attention heads
attention_output = attention_output.transpose(
1, 2).contiguous().view(B, seq_length, d_model)
# Final linear layer to project concatenated heads back to d_model
out = self.fc_out(attention_output)
return out
In this implementation of multi-head attention, the attention mechanism is expanded to use multiple attention heads, allowing the model to focus on different parts of the input sequence simultaneously. This contrasts with the single-head attention, where only one attention head computes a single set of attention scores.
The __init__ method starts by ensuring that the input dimensionality (d_model) is divisible by the number of attention heads (num_heads). Each head will attend to different subspaces of the input. The dimension of each head (head_dim) is calculated as d_model // num_heads, so that when the heads are concatenated, the final output still has dimensionality d_model.
In the forward method, the input tensor x is first projected into query (Q), key (K), and value (V) vectors using three separate linear layers. After this projection, each of the Q, K, and V matrices is reshaped to have multiple heads. This reshaping splits the original tensor into multiple heads of size head_dim. The resulting shapes are (batch_size, num_heads, sequence_length, head_dim), meaning each head processes a part of the input independently.
The attention scores are computed similarly to single-head attention by taking the dot product of the query (Q) and the transpose of the key (K), scaled by the inverse square root of head_dim to ensure stability. After computing the attention scores, a causal mask is applied to prevent attending to future tokens, which is essential for autoregressive models like GPT.
After masking, the attention scores are normalized using the softmax function to compute the attention weights, which represent the importance of each token relative to others in the sequence. The attention weights are then used to compute the weighted sum of the value (V) vectors, producing the final attention output for each head.
At this stage, the outputs of all the attention heads are concatenated back into a single tensor. This is done by transposing the tensor and reshaping it so that the heads are combined, restoring the original dimensionality of d_model. The final concatenated output is passed through a final linear layer, which projects the result back into the same dimensional space as the input (d_model), ensuring consistency for further processing.
The primary difference from single-head attention is that multi-head attention allows the model to compute attention over multiple subspaces of the input at once, enabling it to capture a richer set of relationships between tokens. This makes multi-head attention more powerful, as each head can focus on different parts of the input, leading to more nuanced and diverse attention outputs. In contrast, single-head attention computes a single set of attention scores and outputs, which may be less expressive in capturing complex dependencies in the data.
class MyGPT(nn.Module):
def __init__(self, vocab_size, d_model, max_len=5000,
hidden_dim=2048, use_multiple_head=True, num_heads=8):
...
# Attention layer: Switch between single-head or multi-head attention
if use_multiple_head:
self.attention = MultiHeadAttention(d_model, num_heads)
else:
self.attention = SingleHeadAttention(d_model)
The changes to the model are minimal, and you can seamlessly switch between single-head and multi-head attention without modifying the rest of the code; this approach maintains the flexibility of switching between single and multi-head attention, making it easy to experiment with different configurations of attention layers.
Stacking multiple GPT blocks
Stacking multiple GPT blocks improves the model’s ability to understand complex patterns in sequences. Each block adds a new layer of representation to the input data, which enhances the ability to capture long-range dependencies. As more blocks are stacked, the model refines the contextual understanding of the tokens, leading to better generalization and performance. The attention layers can focus on different aspects of the input at each block, while the feedforward network further transforms the data, allowing the model to progressively build more abstract features.
class MyGPT(nn.Module):
"""
Stacks multiple GPT blocks to create a full GPT model.
"""
def __init__(self, vocab_size, d_model, max_len, hidden_dim,
dropout_prob, n_layers, num_heads,
use_multiple_head):
...
# Stack multiple GPT blocks
self.blocks = nn.ModuleList([
MyGPTBlock(d_model, hidden_dim, dropout_prob,
num_heads, use_multiple_head)
for _ in range(n_layers)
])
# Final layer norm
self.ln_f = nn.LayerNorm(d_model)
# Output projection layer
self.fc_out = nn.Linear(d_model, vocab_size)
In the above code, multiple blocks are stacked to refine the token representations through multiple layers of attention and feedforward networks. Now, let’s explain the internal structure of a single block in detail.
class MyGPTBlock(nn.Module):
"""
Defines a single GPT block, which includes
multi-head attention and feed-forward network.
"""
def __init__(self, d_model, hidden_dim, dropout_prob, num_heads,
use_multiple_head):
super().__init__()
# Attention layer
if use_multiple_head:
self.attention = MultiHeadAttention(d_model, num_heads)
else:
self.attention = SingleHeadAttention(d_model)
# Feedforward neural network
self.ffn = nn.Sequential(
nn.Linear(d_model, hidden_dim), # Expansion
nn.GELU(), # Activation
nn.Linear(hidden_dim, d_model) # Compression
)
# Layer normalization
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
# Dropout for regularization (optional)
self.dropout = nn.Dropout(dropout_prob)
def forward(self, x):
# Apply attention and layer norm
attn_out = self.attention(x)
x = self.ln1(x + attn_out) # Residual connection
# Apply feed-forward network and layer norm
ffn_out = self.ffn(x)
x = self.ln2(x + ffn_out) # Residual connection
x = self.dropout(x) # Apply dropout
return x
The single block consists of two main components: attention and a feedforward neural network. The attention layer is responsible for capturing relationships between tokens, allowing the model to focus on different parts of the input sequence simultaneously. This is achieved either with a single attention head or multiple heads, depending on the configuration. Using multiple heads enables the model to focus on different aspects of the sequence concurrently.
After the attention mechanism, the output is normalized using a LayerNorm to stabilize the training process and ensure better convergence. The model then passes the data through a feedforward neural network, which consists of an expansion layer followed by a compression layer. The expansion increases the dimensionality of the input, while the compression brings it back to the original size. This allows for more complex transformations of the data, leading to a richer representation.
Layer normalization is applied once more after the feedforward network, along with a residual connection to help retain the original input, which is crucial for the flow of gradients during backpropagation. Finally, dropout is applied to reduce overfitting by randomly zeroing out some of the weights during training.
Each block, therefore, progressively refines the input representation by learning deeper and more abstract patterns in the data. When stacked, these blocks form a powerful model capable of capturing long-range dependencies and complex relationships between tokens.
Training routine
The optimizer is initialized using Adam, a commonly used variant of gradient descent. The model.parameters() function provides all the parameters of the model that need to be updated, and lr is the learning rate. The training routine remains the same as the basic model, involving forward and backward passes for each batch, updating gradients using the optimizer, and printing the average loss at the end of each epoch.
Running the model
The process for running the model is unchanged from the basic model case. First, the trained model and vocabulary are loaded, and the input text is tokenized into token IDs. The tokenized sequence is then passed through the model, which predicts the next tokens iteratively. During each iteration, the model generates tokens using temperature scaling and top-k sampling to control randomness and ensure coherent text generation. Once the desired number of tokens is generated, the token IDs are mapped back to text, forming the final generated sequence.
Output example
For the advanced GPT model, I used the same initial prompt as with the basic model, but after training the model for 500 epochs. The generated text shows improvement compared to the basic model in terms of phrase structure and flow, though it is still far from perfect. The phrases now exhibit a more natural progression, and there is a sense of continuity between sentences.
The same prompt was used:
Nel mezzo del cammin di nostra vita
The advanced model generated the following text:
$ python run_model.py
Using tiktoken-based generation
Generated sequence: Nel mezzo del cammin di nostra vita bella; l’altr’ ier, trenta gran rabbia fiorentina,
‘sipa’ Nel vano l’udire ch’entro l’affoca fa vergogna; assai chiara favella,
«Se t’ammentassi da lui acquistar, questa Tolomea, più che ’l mondo spersi? Ché e non vi nòi».
«Donna se non son digiuno». anella è colui che tu chi è quel punto saltò
The output now shows a better flow of phrases compared to the basic model. Although it still lacks complete coherence and semantic clarity, the generated text is structured in a way that mimics natural speech. The improvement in the phrases’ fluidity reflects the benefits of using a more advanced model.
This concludes the creation and demonstration of the GPT model, showcasing the improvements in text generation through enhanced training and architecture.
Model introspection
To better understand the structure and configuration of the model, I implemented a model introspection function. This function outputs relevant parameters such as the number of layers, dimensions of embeddings, and whether multi-head attention is being used. The introspection also calculates and displays the total number of trainable parameters.
class MyGPT(nn.Module):
...
def introspect(self, compile_model=True, device='cpu'):
"""
Prints the model architecture, parameters, and the total
number of parameters.
Optionally compiles the model using `torch.compile`.
Parameters:
- compile_model (bool): If True, compiles the model
using torch.compile().
"""
# Move the model to the specified device
self.to(device)
# Compile the model if requested
if compile_model:
self = torch.compile(self)
# Print the model architecture
print(self)
# Print model configuration
print(f"\nModel Configuration:\n"
f"Vocab Size: {self.vocab_size}\n"
f"Embedding Dim (d_model): {self.d_model}\n"
f"Max Sequence Length: {self.max_len}\n"
f"Hidden Dimension: {self.hidden_dim}\n"
f"Dropout Probability: {self.dropout_prob}\n"
f"Number of Attention Heads: {self.num_heads}\n"
f"Number of Layers: {self.n_layers}\n"
f"Using Multi-Head Attention: {self.use_multiple_head}\n")
# Calculate total trainable parameters
total_params = sum(p.numel() for p in self.parameters()
if p.requires_grad)
print(f"Total Parameters: {total_params:,} "
f"({round(total_params / 1_000_000)}M)\n")
The function first moves the model to the specified device (CPU or GPU) and optionally compiles the model using torch.compile. It then prints the full model architecture, including details of the embedding layer, positional encoding, stacked GPT blocks, and output layers. Additionally, the configuration of the model, such as the vocabulary size, embedding dimensions, hidden dimensions, dropout probability, and number of attention heads, is displayed.
Finally, the total number of trainable parameters is calculated and printed, giving insight into the overall complexity of the model.
Example output:
OptimizedModule(
(_orig_mod): MyGPT(
(wte): Embedding(20792, 1024)
(pe): PositionalEncoding()
(blocks): ModuleList(
(0-7): 8 x MyGPTBlock(
(attention): MultiHeadAttention(
(query): Linear(in_features=1024, out_features=1024, bias=True)
(key): Linear(in_features=1024, out_features=1024, bias=True)
(value): Linear(in_features=1024, out_features=1024, bias=True)
(fc_out): Linear(in_features=1024, out_features=1024, bias=True)
)
(ffn): Sequential(
(0): Linear(in_features=1024, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=2048, out_features=1024, bias=True)
)
(ln1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.25, inplace=False)
)
)
(ln_f): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc_out): Linear(in_features=1024, out_features=20792, bias=True)
)
)
Model Configuration:
Vocab Size: 20792
Embedding Dim (d_model): 1024
Max Sequence Length: 512
Hidden Dimension: 2048
Dropout Probability: 0.25
Number of Attention Heads: 4
Number of Layers: 8
Using Multi-Head Attention: True
Total Parameters: 109,803,832 (110M)
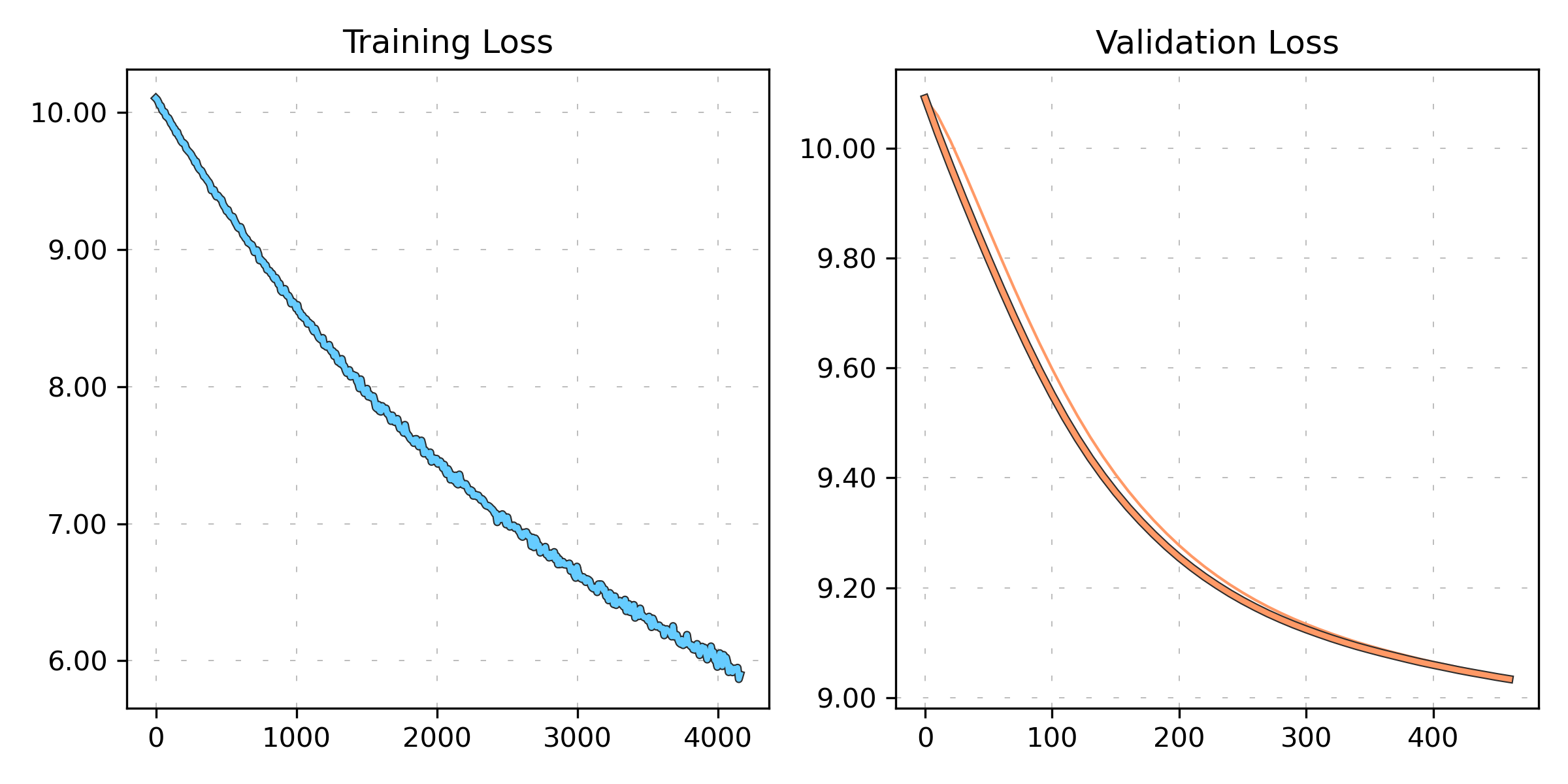
Loss visualization
Once one or more training runs have been completed, it is possible to visualize the training and validation loss using either a simple or exponential moving average to smooth the data. This provides a clearer view of the trend in the loss values by reducing noise.
Below is an example of how you can visualize the smoothed training and validation loss:
def simple_moving_average(data, window_size):
sma = []
for i in range(len(data)):
if i < window_size:
sma.append(sum(data[:i + 1]) / (i + 1))
else:
sma.append(sum(data[i - window_size + 1:i + 1]) / window_size)
return sma
def exponential_moving_average(data, alpha):
ema = [data[0]]
for i in range(1, len(data)):
ema.append(alpha * data[i] + (1 - alpha) * ema[i - 1])
return ema
def visualize_loss(logdir, plot_val_loss, use_sma, ema_alpha, sma_window_size):
...
if use_sma:
y_train_smoothed = simple_moving_average(y_train, sma_window_size)
y_val_smoothed = simple_moving_average(y_val, sma_window_size)
else:
y_train_smoothed = exponential_moving_average(y_train, ema_alpha)
y_val_smoothed = exponential_moving_average(y_val, ema_alpha)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(x_train, y_train_smoothed, label="Training Loss Smoothed", color='b', linewidth=1.0)
ax1.set_title("Training Loss")
if plot_val_loss:
ax2 = fig.add_subplot(1, 2, 2)
create_axes(ax2, y_val)
ax2.plot(x_val, y_val_smoothed, label="Validation Loss Smoothed", color='orange', linewidth=1.0)
ax2.plot(x_val, y_val, label="Validation Loss", color='k', linewidth=2.0)
ax2.set_title("Validation Loss")
plt.show()
This function visualizes the loss values and their smoothed versions using either a simple or exponential moving average. You can toggle between training and validation loss and control the smoothing effect by modifying the sma_window_size for the simple moving average or the ema_alpha for the exponential moving average.
The following plot illustrates the results of a 500-epoch run:
Complete code and results
The complete code for the model implementation, training, and visualization are available on GitHub. The repository contains detailed instructions on how to set up the environment, train the model, generate text, and visualize the training and validation losses.
The repository is available at the following link.