Large Language Models (LLMs) Overview
Transformer networks
I have been already describing as part of my neural network overview Transformer networks here, but I want now to go through in more details since they have revolutionized natural language processing by introducing attention mechanisms that allow for parallel processing of input data, as opposed to the sequential nature of traditional recurrent networks. This enables more efficient handling of long-range dependencies in sequences, making them ideal for tasks like machine translation, text generation, and language understanding, while also serving as the foundation for advanced models like GPT and BERT.
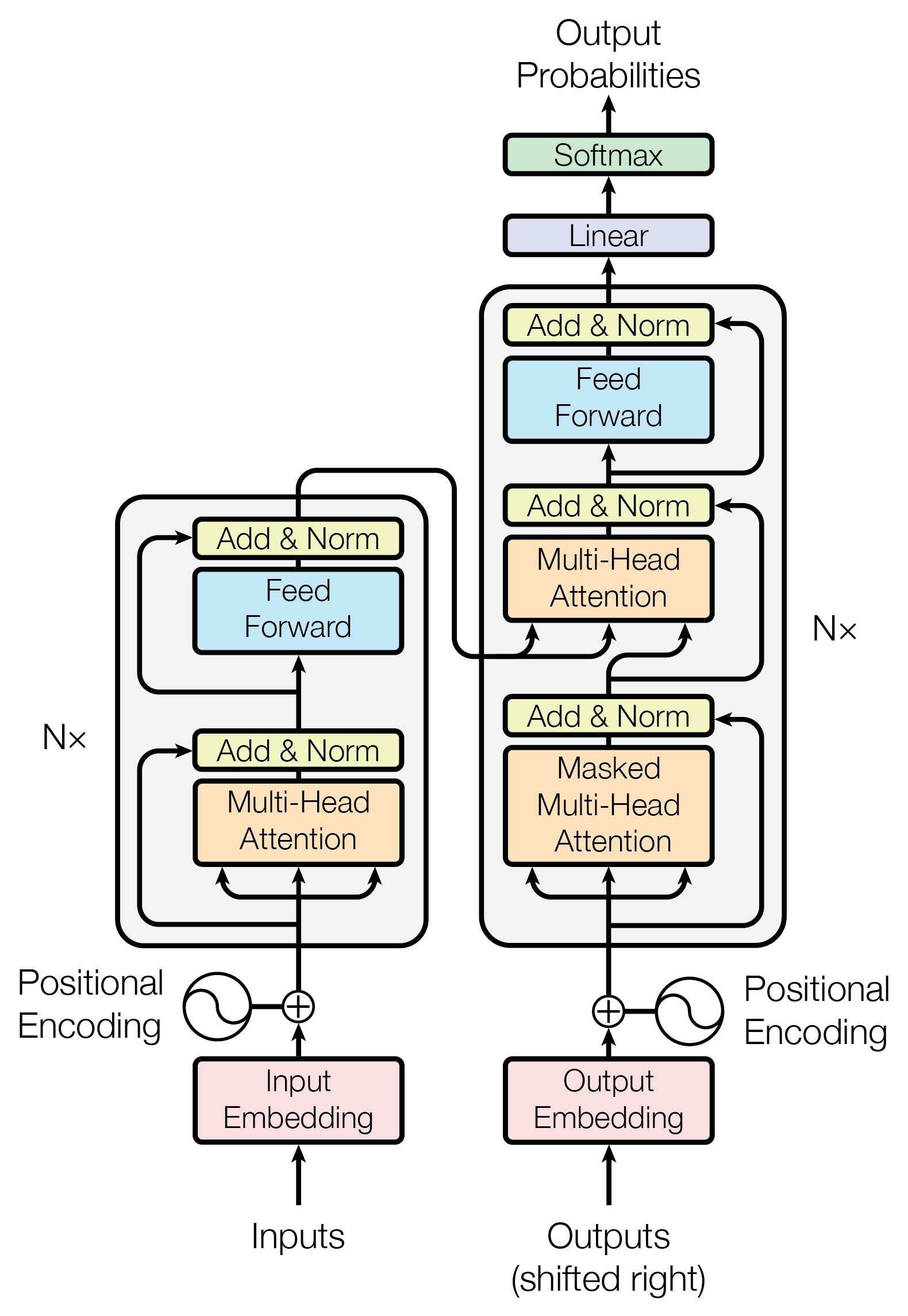
The Transformer architecture was first introduced in the paper “Attention is All You Need” by Google researchers in 2017. The architecture of a transformer-based language model typically consists of the following components:
-
Embedding Layer: Converts input tokens (words or subwords) into dense vectors. These embeddings are enriched with positional encodings to capture word order.
-
Encoder: The encoder is composed of multiple layers of multi-head self-attention mechanisms and feed-forward networks. The self-attention mechanism allows the model to weigh the importance of different words in the input relative to each other, capturing context efficiently. Each layer also includes residual connections and layer normalization.
-
Decoder: Like the encoder, the decoder consists of multiple layers of multi-head attention and feed-forward networks. The decoder includes an additional attention mechanism to focus on the encoder’s output. This helps the decoder generate output based on both the input sequence and the previously generated tokens.
-
Output Layer: The final layer generates probabilities for each token in the vocabulary, predicting the next token or word in the sequence based on the decoder’s output. The prediction is typically done using a softmax function.
Attention
The attention mechanism is the central innovation of the Transformer architecture, reshaping how models handle sequential data in natural language processing. Unlike traditional models that process sequences sequentially, the attention mechanism allows the model to consider all positions in the input simultaneously. This means that each word in a sentence can directly relate to every other word, regardless of their position, enabling the model to capture dependencies over long distances more effectively.
At its core, the attention mechanism operates by computing a set of attention weights that determine the relevance of other words in the sequence to a particular word. For each word in the input, the model generates three vectors through linear transformations: the query, the key, and the value. These vectors are derived from the word embeddings and are essential for calculating how much attention to pay to other words.
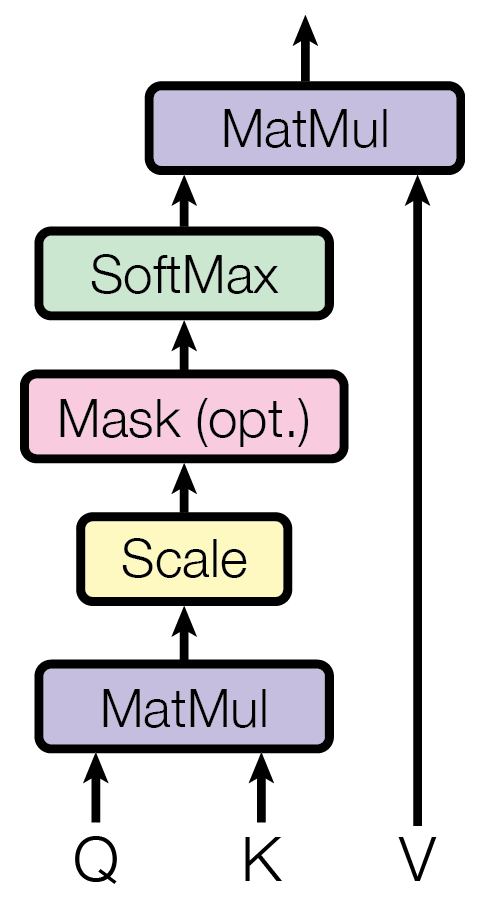
The process involves taking the query vector of a word and computing dot products with the key vectors of all words in the sequence. These dot products measure the compatibility or similarity between the query and the keys. The results are then scaled and passed through a softmax function to obtain normalized attention weights, which reflect the importance of each word in the context of the current word.
Let’s suppose we have a sequence of words, and for each word i, we have a query vector \mathbf{q}_i, a key vector \mathbf{k}_i, and a value vector \mathbf{v}_i. For a given query vector \mathbf{q}_i, we compute the attention scores with all key vectors in the sequence by calculating the dot products:
e_{ij} = \mathbf{q}_i^\top \mathbf{k}_j
These scores e_{ij} represent the raw attention weights between the query at position i and the keys at all positions j. To prevent the dot products from becoming too large, which can lead to issues like vanishing or exploding gradients, the scores are scaled by the square root of the dimension of the key vectors, denoted as \sqrt{d_k}:
\tilde{e}_{ij} = \frac{e_{ij}}{\sqrt{d_k}}
Next, the scaled scores \tilde{e}_{ij} are passed through the softmax function to obtain the normalized attention weights \alpha_{ij}:
\alpha_{ij} = \frac{e^{\tilde{e}_{ij}}}{\sum_{k=1}^{n} e^{\tilde{e}_{ik}}}
Here, n is the number of words in the sequence. The softmax function converts the scaled scores into probabilities that sum to 1 across all positions j for each query i. These attention weights indicate the relative importance of each word in the sequence with respect to the current word.
Finally, the attention weights \alpha_{ij} are used to compute a weighted sum of the value vectors \mathbf{v}_j, resulting in a new representation \mathbf{z}_i for each word:
\mathbf{z}_i = \sum_{j=1}^{n} \alpha_{ij} \mathbf{v}_j
This new representation \mathbf{z}_i incorporates information from all words in the sequence, weighted by their relevance to the current word as determined by the attention weights. By performing this process for each word in the sequence, the attention mechanism allows the model to capture contextual relationships and dependencies across the entire input. This enables the model to focus on the most relevant parts of the input when generating representations, effectively capturing both local and global context in the data.
These attention weights are used to create a weighted sum of the value vectors, producing a new representation for each word that incorporates information from the entire sequence. This allows the model to focus on relevant parts of the input when processing each word, effectively capturing context and relationships between words.
Multi-head attention
An extension of this concept is the multi-head attention mechanism, which runs several attention mechanisms, or “heads,” in parallel. Each head operates in a different subspace of the embedding, allowing the model to capture various types of relationships and patterns simultaneously. The outputs of all the heads are then concatenated and projected to form the final representation.
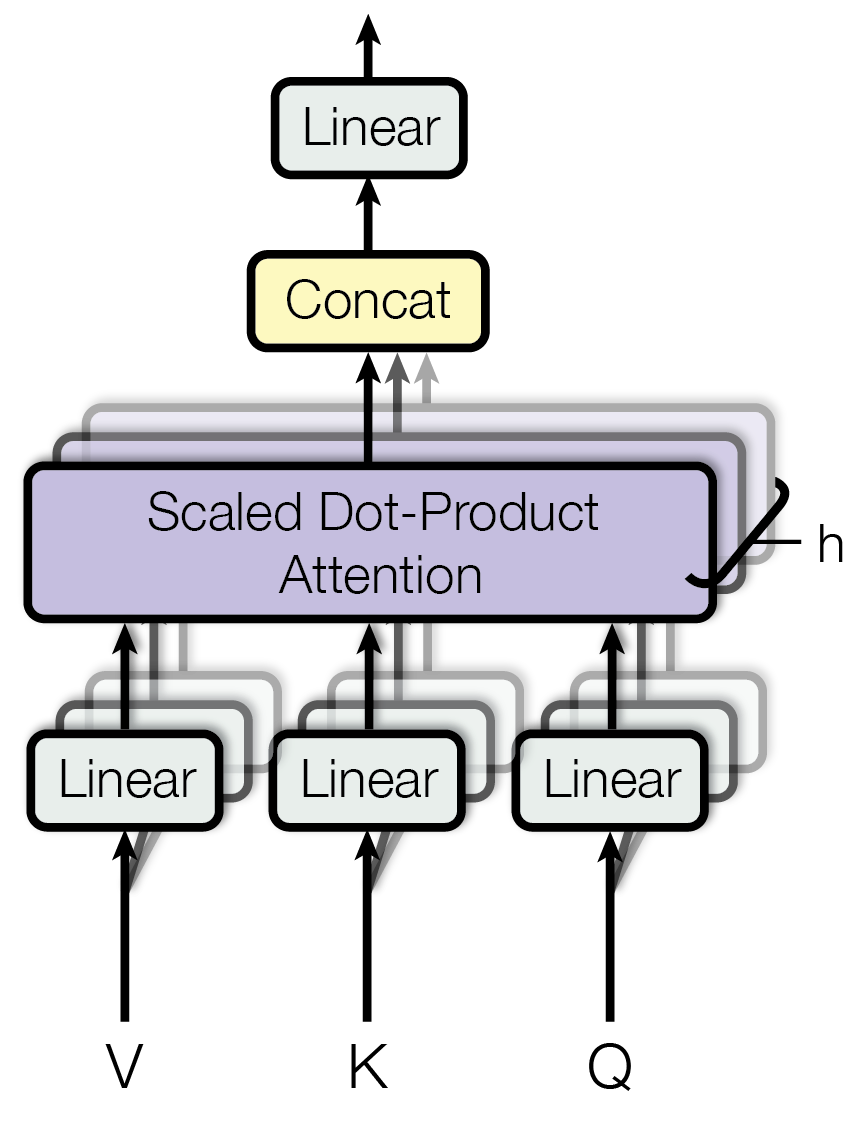
Let’s consider that instead of performing a single attention operation with queries, keys, and values, the model applies multiple attention functions simultaneously. For each head h (where h = 1, 2, \dots, H and H is the total number of heads), the model projects the input embeddings into different query, key, and value spaces using learned linear transformations. Specifically, for an input sequence of length n with embeddings of dimension d_{\text{model}}, the transformations are:
\mathbf{Q}_h = \mathbf{X} \mathbf{W}_h^Q, \quad \mathbf{K}_h = \mathbf{X} \mathbf{W}_h^K, \quad \mathbf{V}_h = \mathbf{X} \mathbf{W}_h^V
Here, \mathbf{X} \in \mathbb{R}^{n \times d_{\text{model}}} represents the input embeddings, and \mathbf{W}_h^Q, \mathbf{W}_h^K, \mathbf{W}_h^V \in \mathbb{R}^{d_{\text{model}} \times d_k} are the weight matrices for the queries, keys, and values of head h. The dimension d_k is typically set to d_{\text{model}} / H to keep the computational cost consistent.
Each head then computes attention as:
\text{Attention}_h(\mathbf{Q}_h, \mathbf{K}_h, \mathbf{V}_h) = \text{softmax}\left( \frac{\mathbf{Q}_h \mathbf{K}_h^\top}{\sqrt{d_k}} \right) \mathbf{V}_h
This produces an output \mathbf{Z}_h \in \mathbb{R}^{n \times d_k} for each head. The scaling factor \sqrt{d_k} ensures that the dot products do not become too large, which could adversely affect the gradients during training.
After computing the attention outputs for all heads, the model concatenates these outputs along the feature dimension to form a combined matrix:
\mathbf{Z} = \text{Concat}(\mathbf{Z}_1, \mathbf{Z}_2, \dots, \mathbf{Z}_H) \in \mathbb{R}^{n \times (H \cdot d_k)}
This concatenated matrix \mathbf{Z} is then projected back to the original embedding space dimension d_{\text{model}} using a final linear transformation:
\mathbf{Y} = \mathbf{Z} \mathbf{W}^O
Here, \mathbf{W}^O \in \mathbb{R}^{(H \cdot d_k) \times d_{\text{model}}} is the output projection matrix, and \mathbf{Y} \in \mathbb{R}^{n \times d_{\text{model}}} is the final output of the multi-head attention mechanism:
- The input embeddings \mathbf{X} reside in the space \mathbb{R}^{n \times d_{\text{model}}}.
- The projections to queries, keys, and values map from \mathbb{R}^{d_{\text{model}}} to \mathbb{R}^{d_k} for each head.
- The attention outputs \mathbf{Z}_h for each head are in \mathbb{R}^{n \times d_k}.
- The concatenated output \mathbf{Z} spans the space \mathbb{R}^{n \times (H \cdot d_k)}.
- The final output \mathbf{Y} is projected back into \mathbb{R}^{n \times d_{\text{model}}}.
By operating in different subspaces, each attention head can focus on different types of relationships within the data. One head might capture syntactic dependencies, while another captures semantic relationships. This parallel processing enhances the model’s ability to represent complex patterns and dependencies in the input sequence, ultimately improving performance on tasks that require understanding intricate structures in the data.
The attention mechanism’s ability to model relationships without regard to distance makes it particularly powerful. It overcomes the limitations of earlier models like recurrent neural networks, which struggled with long-range dependencies due to their sequential nature and issues like the vanishing gradient problem. Moreover, since attention mechanisms allow for parallel computation, they significantly reduce training times compared to sequential models.
This approach permitted the development of language models by enabling them to understand context more effectively and handle complex language tasks. It has led to improvements in machine translation, text summarization, and question-answering systems. The attention mechanism’s efficiency and effectiveness are key reasons behind the success of large language models, as it allows them to process and learn from vast amounts of data, capturing intricate patterns in human language.
Examples
Generative Pre-trained Transformer (GPT) developed by OpenAI stands as one of the most well-known implementations of the Transformer architecture. GPT is an autoregressive language model that excels in generating coherent and contextually relevant text by predicting the next word in a sequence based on the preceding words. Its extensive pre-training on vast amounts of text data allows it to capture intricate language patterns and nuances. Post pre-training, GPT can be fine-tuned for a variety of applications such as text completion, translation, summarization, and question answering, showcasing its remarkable versatility and ability to produce human-like text.
BERT (Bidirectional Encoder Representations from Transformers), introduced by Google, takes a different approach by employing a bidirectional training mechanism. This allows BERT to understand the context of a word based on both its left and right surroundings within a sentence, enhancing its capability in tasks that require deep comprehension of language context, such as sentiment analysis, named entity recognition, and question answering. BERT’s architecture consists solely of the encoder part of the Transformer, making it particularly effective for tasks focused on understanding and interpreting input text.
Text-to-Text Transfer Transformer (T5), also developed by Google, adopts a unified framework by treating every language problem as a text-to-text task. Whether it’s translation, summarization, classification, or more complex tasks like question answering, T5 converts all inputs and outputs into plain text. This uniform approach simplifies the model architecture and training process, allowing T5 to be fine-tuned on a wide variety of tasks without the need for task-specific modifications. By leveraging this text-to-text paradigm, T5 achieves impressive performance across numerous benchmarks, highlighting the flexibility and power of the Transformer architecture.
RoBERTa (Robustly optimized BERT approach), developed by Facebook AI, builds upon BERT’s foundation by optimizing the training process. RoBERTa utilizes larger datasets, removes the next sentence prediction objective, and increases the training duration. These modifications result in improved performance on various natural language understanding benchmarks, demonstrating that careful tuning and scaling of Transformer-based models can lead to substantial gains in effectiveness.
LLaMA (Large Language Model Meta AI), introduced by Meta (formerly Facebook), represents another significant advancement in Transformer-based models. LLaMA is designed to be a more efficient and accessible large language model, aiming to democratize access to powerful AI by providing models that are competitive with state-of-the-art counterparts while being less resource-intensive. LLaMA models come in various sizes, catering to different computational budgets and application needs. By optimizing training techniques and model architectures, LLaMA achieves high performance on a range of language tasks, making it a valuable tool for both research and practical applications.
Transformer-XL and XLNet extend the capabilities of the original Transformer architecture by addressing its limitations regarding long-range dependencies and fixed-length context windows. Transformer-XL introduces a recurrence mechanism that allows the model to capture longer-term dependencies beyond the fixed context size, making it more adept at handling lengthy sequences. XLNet, on the other hand, combines the strengths of autoregressive and autoencoding models by using a permutation-based training objective, enabling it to model bidirectional contexts without relying on masked language modeling. These advancements enhance the ability of Transformer-based models to understand and generate complex and extended pieces of text.
Each of these Transformer-based models exemplifies the versatility and robustness of the Transformer architecture, demonstrating its ability to adapt and excel across a wide spectrum of natural language processing tasks. By building upon the fundamental attention mechanisms, these models continue to push the boundaries of what is possible in language understanding and generation, driving forward advancements in artificial intelligence and machine learning.
Limitations
While Large Language Models (LLMs) have revolutionized the field of natural language processing with their remarkable ability to generate coherent and contextually relevant text, they are not without their inherent limitations.
One of the primary limitations of LLMs is their reliance on static training data. These models are trained on vast amount of text up to a specific cutoff date, which means they lack awareness of events, developments, or emerging knowledge that occur after this period. Consequently, LLMs cannot provide real-time information or updates unless they are retrained or augmented with external data sources. This static nature also contributes to the phenomenon of “knowledge cutoff,” where the model’s understanding of the world is frozen at the time of its last training update.
Another significant limitation is the propensity for LLMs to generate plausible-sounding but factually incorrect or nonsensical responses, a behavior commonly referred to as “hallucination.” Despite their impressive language generation capabilities, LLMs do not possess true understanding or reasoning abilities. Instead, they predict text based on patterns in the training data, which can sometimes lead to the creation of inaccurate or misleading information. This issue poses substantial risks, especially in applications requiring high factual accuracy, such as medical advice, legal consultations, or educational content.
LLMs also face challenges related to context retention and long-term dependencies. While they excel at handling short to moderately long inputs, maintaining coherence and relevance over extended conversations or documents can be problematic. The models may lose track of earlier parts of the conversation, leading to inconsistencies or repetitive responses. This limitation hampers their effectiveness in applications that require sustained and nuanced interactions, such as in-depth customer support or complex storytelling.
Bias and fairness represent another critical area of concern. LLMs inherit biases present in their training data, which can manifest in various forms; these biases can lead to the generation of content that is discriminatory, offensive, or perpetuates stereotypes.
Privacy and security issues also pose significant challenges. Since LLMs are trained on extensive datasets that may include sensitive or proprietary information, there is a risk of inadvertently generating content that reveals private data or intellectual property. Ensuring that models do not leak such information requires robust data handling practices and advanced techniques like differential privacy, which are still areas of active research and development.
Additionally, LLMs lack true understanding and consciousness. They operate purely based on statistical correlations in data without any form of awareness, intention, or comprehension of the content they generate. This fundamental limitation means that while LLMs can mimic human-like text generation, they do not possess genuine cognitive abilities or emotional intelligence, which are essential for tasks requiring empathy, ethical judgment, or creative problem-solving.
Finally, the interpretability and transparency of LLMs remain significant concerns. The complex and opaque nature of these models makes it difficult to understand how they arrive at specific outputs, hindering efforts to diagnose errors, improve performance, or ensure accountability.
Enhancements
In response to the inherent limitations of Large Language Models (LLMs), recent advancements have focused on developing technical enhancements that address issues such as bias, factual inaccuracies, and the static nature of their knowledge bases. These enhancements leverage sophisticated algorithms and architectural innovations to improve the fairness, reliability, and adaptability of LLMs.
For instance, techniques like Debiasing Algorithms systematically identify and mitigate biased representations within the training data, ensuring more equitable and unbiased outputs. Additionally, Knowledge Integration Methods such as Retrieval-Augmented Generation (RAG) enable models to access and incorporate up-to-date information from external sources, thereby enhancing their accuracy and relevance.
Other notable advancements include Contextual Embedding Adjustments, which refine how models understand and generate contextually appropriate responses, and Modular Architectures that allow for more flexible and scalable model updates without extensive retraining.
These technical enablers not only enhance the performance of LLMs but also make them more resilient to the challenges posed by dynamic and diverse real-world applications.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an extension of Large Language Models, addressing several key limitations by integrating retrieval mechanisms with generative capabilities. Unlike traditional LLMs that rely solely on their pre-trained knowledge, RAG leverages an external knowledge base to fetch relevant information in real-time, thereby grounding the generated responses in verified and up-to-date data.
This dual-component system comprises a Retriever, which efficiently searches through vast datasets to identify pertinent documents or passages related to the input query, and a Generator, which synthesizes this retrieved information to produce coherent and accurate responses. By incorporating external data sources, RAG significantly reduces the occurrence of hallucinations—where models generate plausible but incorrect information—and ensures that the outputs are both contextually relevant and factually sound.
Moreover, RAG enhances the scalability and flexibility of LLMs, as the knowledge base can be continuously updated without the need for extensive retraining of the generative model. This makes RAG particularly effective for applications requiring precise and current information, such as customer support, research assistance, and content creation. Overall, RAG exemplifies how technical innovations can synergize retrieval and generation processes to overcome the static and sometimes unreliable nature of traditional LLMs, paving the way for more robust and dependable AI-driven solutions.
Fine-Tuning
Fine-Tuning is another enhancement technique that involves adapting a pre-trained model to perform specific tasks or operate within particular domains. Building upon the knowledge acquired during extensive pre-training on diverse and large-scale datasets, fine-tuning refines the model’s capabilities by training it further on a more targeted dataset tailored to the desired application.
This process enables LLMs to achieve higher accuracy and relevance in specialized areas, such as legal analysis, medical diagnostics, or technical support, by exposing them to domain-specific terminology, context, and nuances.
This technique enhances the model’s ability to understand and generate content that aligns closely with the specific requirements and constraints of various applications, thereby improving overall performance and user satisfaction.
For example, a general-purpose LLM can be fine-tuned on customer service interactions to better handle support queries, or on scientific literature to assist researchers in summarizing complex studies. By providing a mechanism to tailor LLMs to precise needs without the need for training from scratch, fine-tuning offers a scalable and efficient approach to leveraging the versatility of large language models across a wide array of specialized tasks and industries.
References
VASWANI, Ashish, SHAZEER, Noam, PARMAR, Niki, USZKOREIT, Jakob, JONES, Llion, GOMEZ, Aidan N., KAISER, Lukasz and POLOSUKHIN, Illia, 2017. Attention Is All You Need. arXiv preprint arXiv:1706.03762.